执行Python脚本
访问路径:数据功能 -> Python脚本执行
功能简述
该模块提供执行特定的Python代码段或项目包功能,适用于使用Python代码完成特殊逻辑处理的业务场景需求。为了可以同仓鼠平台整合,系统在运行用户提交的代码时,会通过命名参数的方式向代码提供必要的系统运行环境参数,如代码运行的实际路径,以及系统临时创建的工作库访问连接信息等,便于代码与系统进行很好的整合和互动。
脚本支持模式:
- 代码段模式:提供简单的、快速代码段执行。(代码中调用的功能包需在工作站上预安装)
- 项目包模式:提供完整的、结构化项目代码执行,项目代码以
.pyz模式打包,代码包可以使用专有的功能模块。
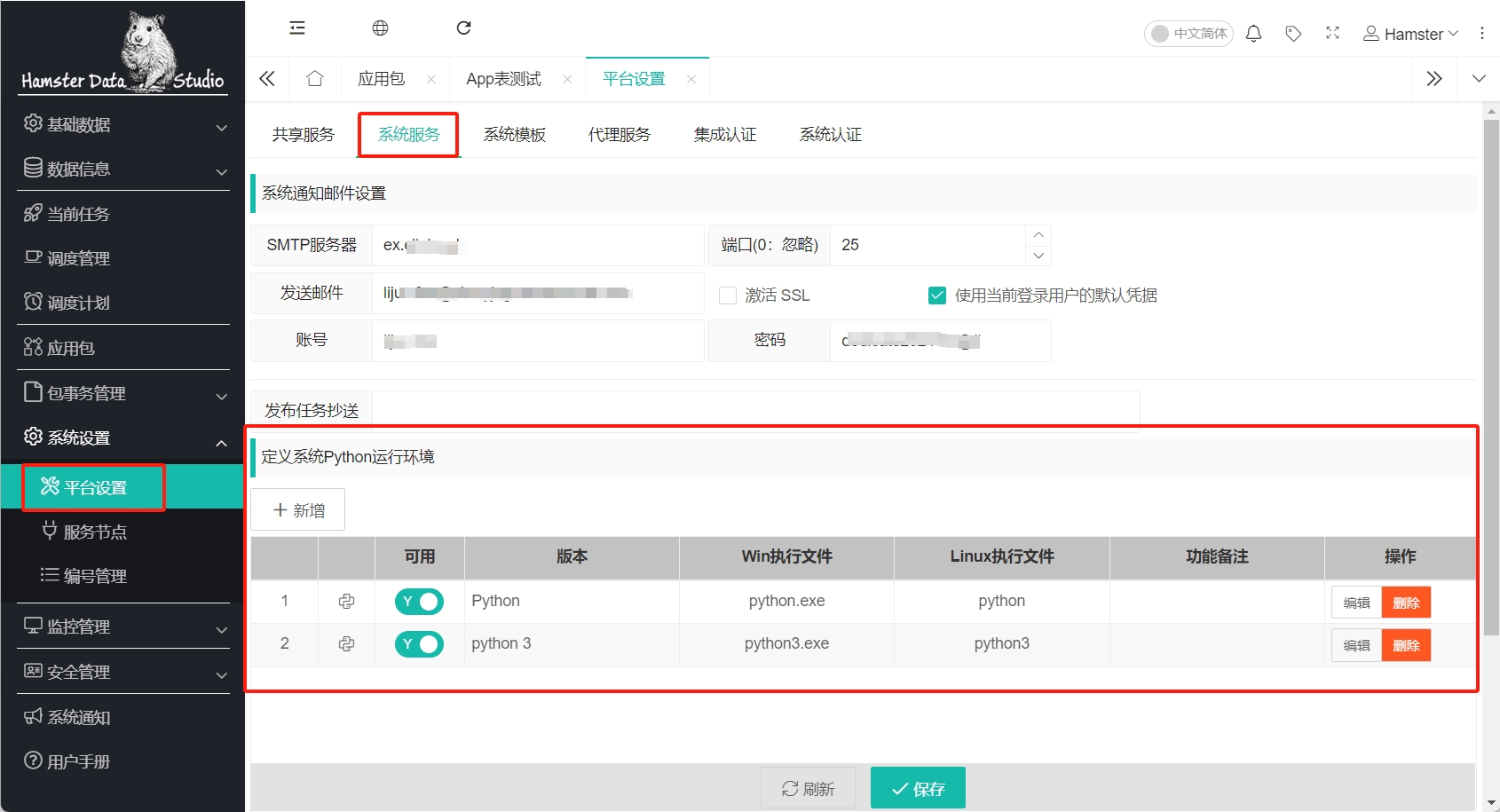
环境准备
在工作站Slaver上需要预安装好对应的Python版本运行环境,并在系统配置中注册完成。
创建任务
-
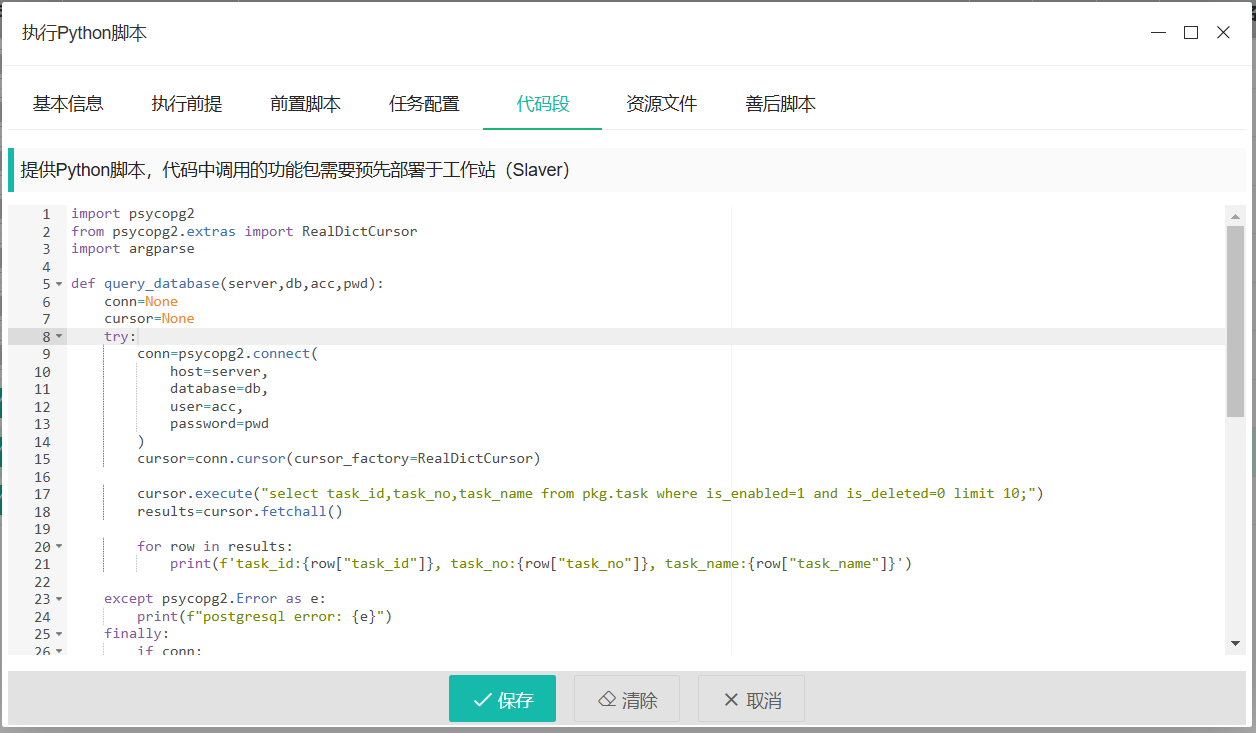
代码段模式
该模式下,用户可以提供精简的Python脚本(单文件),代码中涉及到的功能包需要预先在对应的工作站(Slaver)Python运行环境中已经安装好。
-
项目包模式
该模式下,用户可以在任务包的预定义模板功能中,先上传一个完整的项目包,含结构化代码(多文件)或相关的资源文件。同时,支持调用专有的(未在工作站上默认安装的)功能包。项目文件以打包的压缩文件格式
.pyz进行上传,具体操作可以参考:Python项目打包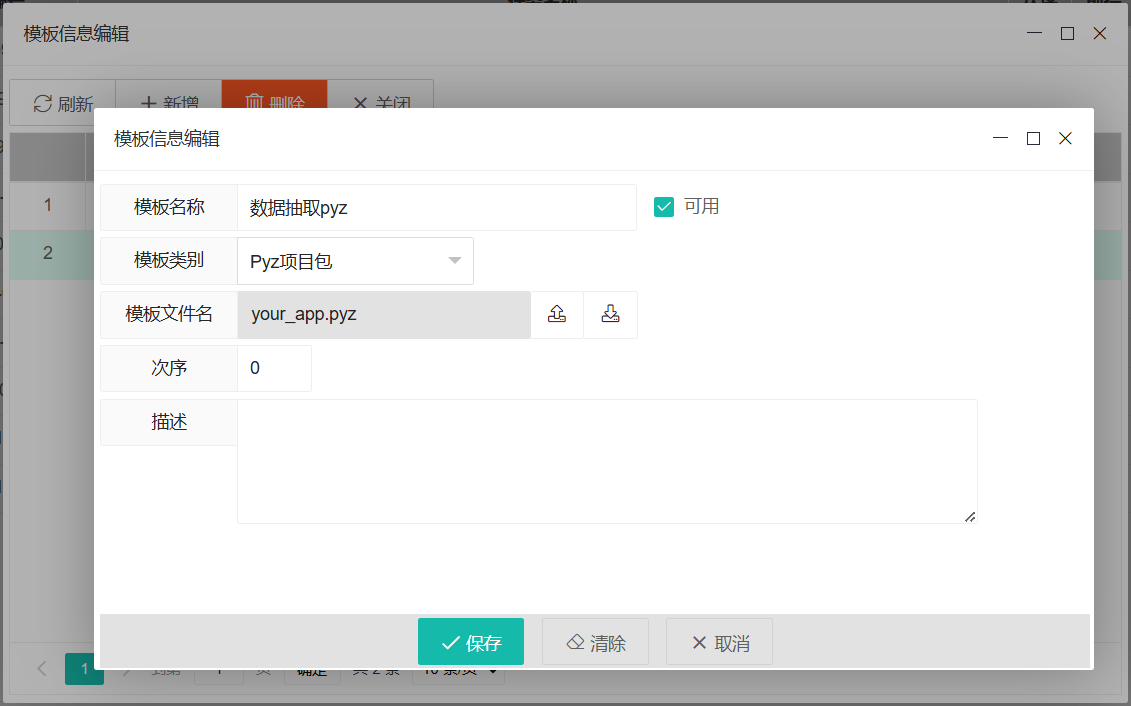
在具体任务中,选择
项目包模板,并选择上述提交的项目包。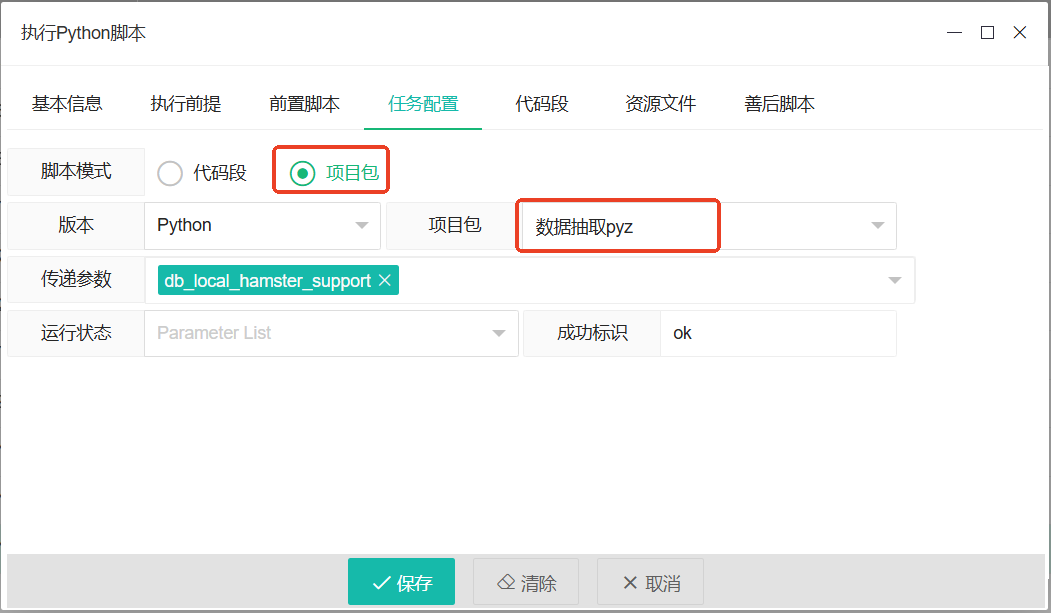
参数配置
-
参数输入
在调用Python任务时,系统将通过调用参数的方式将任务执行时所需的外部参数传递给代码,如运行参数、数据库连接信息等,便于代码与运行环境进行交互。
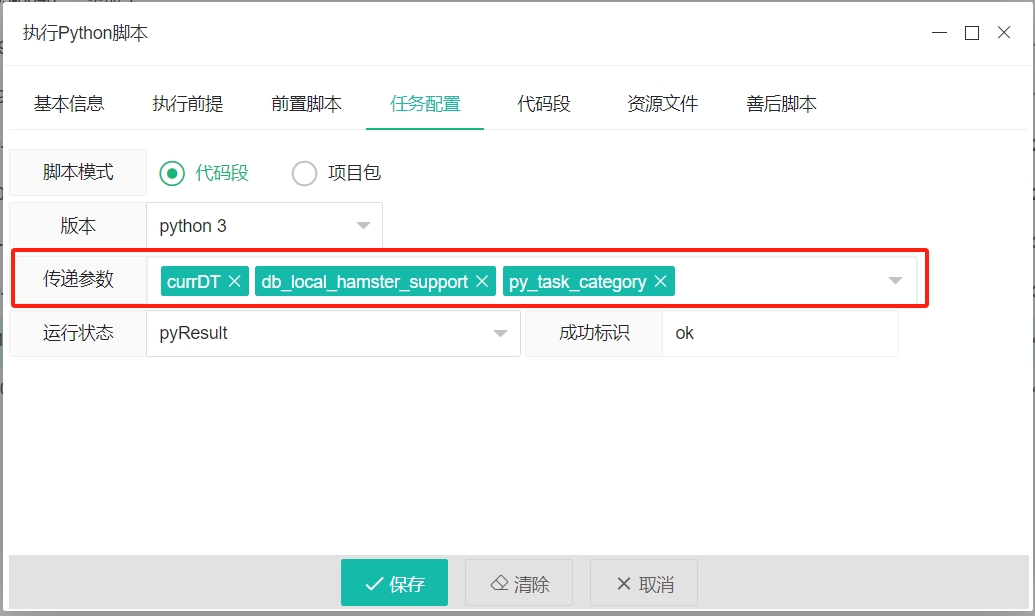
- 脚本模式:选择提供执行代码的不同方式
- 传递参数-数据库变量:用户可以预定义一个
数据连接参数,然后选择一个具体的数据库,便于Python代码中进行访问。运行时,仓鼠系统会依据数据库类型提取通用的数据库连接信息,具体内容可以参考通用数据连接,作为使用相同的变量名称来创建命名参数传入python代码。用户在python代码中可以解析并提取所需要的连接信息。因为连接信息以JSON格式传入,为了避免不同的运行环境对参数格式的解析的差异,仓鼠系统将JSON字符串先转换成Base64字符串后,以命名参数的模式传入。用户在python代码中可以将其还原成JSON字符串即可使用。如:db_local_hamster_support变量。调用时,系统会传入类似下述的命名参数。
# 初始传入时的Base64值
--db_local_hamster_support= "eyJEc0NhdGVnb3J5IjoiUG9zdGdyZVNRTCIsIkhvc3QiOiIxMjcuMC4wLjEiLCJQb3J0Ijo1NDMyLCJEYk5hbWUiOiJoYW1zdGVyX3N1cHBvcnRfMjAyNCIsIlVzZXJJZCI6InBvc3RncmVzIiwiVXNlclB3ZCI6ImFiYzEyMzQ1NiIsIlRpbWVvdXQiOjEyMCwiSXNEYkJhc2VkQ29ubmVjdGlvbiI6dHJ1ZSwiSXNGb3JTU0lTUGFja2FnZSI6ZmFsc2V9"
# 解析后的JSON值
db_local_hamster_support: {"DsCategory":"PostgreSQL","Host":"127.0.0.1","Port":5432,"DbName":"hamster_support_2024","UserId":"postgres","UserPwd":"abc123456","Timeout":120,"IsDbBasedConnection":true,"IsForSSISPackage":false}- 传递参数-自定义变量(非数据连接参数): 调用时,系统会获取当前变量值,作为命名参数传入。如:
curDT,py_task_category。
--curDT="2024-10-27 11:27:00" --py_task_category="ExecPython"- 传递参数-系统变量:除了上述用户自定义变量外,仓鼠系统还会额外传入和运行环境相关的系统环境命名参数:
# sys_working_folder
# 当前Python任务所在的工作目录,具体路径会由appsetting中的配置项确定。
# 相关的资源文件都会存放在该目录中
# 路径地址格式会由当前运行系统格式确定,如Windows:
--sys_working_folder= "D:\Hamster Studio\Working_Folder\89eb3f27-743c-4316-89fa-da4958925e12\cb9c1ced-9c5d-4a01-8601-e3ba04929bde"
# Linux环境:
--sys_working_folder= "/hamster/working_folder/89eb3f27-743c-4316-89fa-da4958925e12/cb9c1ced-9c5d-4a01-8601-e3ba04929bde"
# sys_working_db_conn_string
# 如果当前任务包有创建临时的工作库,则运行时,系统将自动添加上述数据库连接字符串命名参数,该值为Base64码,转换成JSON格式即可以在Python代码中访问工作库用
--sys_working_db_conn_string= "eyJEc0NhdGVnb3J5IjoiUG9zdGdyZVNRTCIsIkhvc3QiOiIxMjcuMC4wLjEiLCJQb3J0Ijo1NDMyLCJEYk5hbWUiOiJwa2cyMDI0MDkwMDAxX2M2NDY2MzI4ZWMzMDQ1ZWRiZWFjN2ZlMzJkZjdmNjZlIiwiVXNlcklkIjoiaG1fYzY0NjYzMjhlYzMwNDVlZGJlYWM3ZmUzMmRmN2Y2NmUiLCJVc2VyUHdkIjoiNmFmYmUxZWE5M2EzYzZlNGZhNTNmNDRmODhmYzI4NzAiLCJUaW1lb3V0IjoxMjAsIklzRGJCYXNlZENvbm5lY3Rpb24iOnRydWUsIklzRm9yU1NJU1BhY2thZ2UiOmZhbHNlfQ=="- 运行状态:如果选定自定义参数的话,可以将py代码最后
print()出来的内容保存到这个变量里面。 - 成功标识:如果设置了值,则会和py代码最后
print()出来的内容进行比对,如果匹配的话,则表明任务执行成功,否则视为任务执行失败。如果不设置,则不做判断。
-
代码案例
可以参考下述参数调用案例:
import psycopg2
from psycopg2.extras import RealDictCursor
import argparse
import json
import base64
# 数据库访问功能
def query_database(server,db,acc,pwd):
conn=None
cursor=None
try:
conn=psycopg2.connect(
host=server,
database=db,
user=acc,
password=pwd
)
cursor=conn.cursor(cursor_factory=RealDictCursor)
cursor.execute("select task_id,task_no,task_name from pkg.task where is_enabled=1 and is_deleted=0 limit 10;")
results=cursor.fetchall()
for row in results:
print(f'task_id:{row["task_id"]}, task_no:{row["task_no"]}, task_name:{row["task_name"]}')
except psycopg2.Error as e:
print(f"postgresql error: {e}")
finally:
if conn:
cursor.close()
conn.close()
def main():
parser=argparse.ArgumentParser(description='Query postgresql data')
parser.add_argument('--db_local_hamster_support',required=True,help='pg connection string')
parser.add_argument('--sys_working_db_conn_string',required=True,help='wkr db connection string')
parser.add_argument('--currDT', required=False, help='Current date and time')
parser.add_argument('--sys_working_folder', required=False, help='System working folder')
# 解析参数
args, unknowargs = parser.parse_known_args()
print(f"currDT:{args.currDT}")
print(f"wkr_folder:{args.sys_working_folder}")
# 获取工作库连接信息(如果需要的话)
print(f"sys_working_db_conn_string base64:{args.sys_working_db_conn_string}")
wkr_db_base64_bytes=args.sys_working_db_conn_string.encode('utf-8')
wkr_db_json_bytes=base64.b64decode(wkr_db_base64_bytes)
wkr_db_json_str=wkr_db_json_bytes.decode('utf-8')
print(f"sys_working_db_conn_string:{wkr_db_json_str}")
# 解析连接字符串,并提取参数
wkr_db_conn_data=json.loads(wkr_db_json_str)
# 获取自定义数据库参数的连接信息(如果有的话)
print(f"db_local_hamster_support base64:{args.db_local_hamster_support}")
parm_db_base64_bytes=args.db_local_hamster_support.encode('utf-8')
parm_db_json_bytes=base64.b64decode(parm_db_base64_bytes)
parm_db_json_str=parm_db_json_bytes.decode('utf-8')
print(f"db_local_hamster_support:{parm_db_json_str}")
# 解析连接字符串,并提取参数
conn_data=json.loads(parm_db_json_str)
server=conn_data['Host']
database=conn_data['DbName']
user=conn_data['UserId']
password=conn_data['UserPwd']
query_database(server,database,user,password)
# 创建符合要求的Python字典,用于保存返回变量值
data = {
"errmsg": "ok",
"results": {
"user_name": "johnson",
"file_name": "summary_report.png"
}
}
# 将字典序列化为JSON格式的字符串
json_string = json.dumps(data)
# 输出序列化后的JSON字符串,便于通知仓鼠系统更新同名参数值
print(json_string)
if __name__=='__main__':
main() -
资源文件
如果代码执行时需要一些外部资源文件,如图片、数据csv文件,包括前置任务生成的报表文件等,都可以通过该功能预先提交。任务具体执行前,仓鼠系统会在工作站上创建专用的工作目录,并将预提交的资源文件导出到工作目录中。同时通过命名的系统工作目录变量
--sys_working_folder="xxx/xxx"将具体的工作路径传递给执行代码。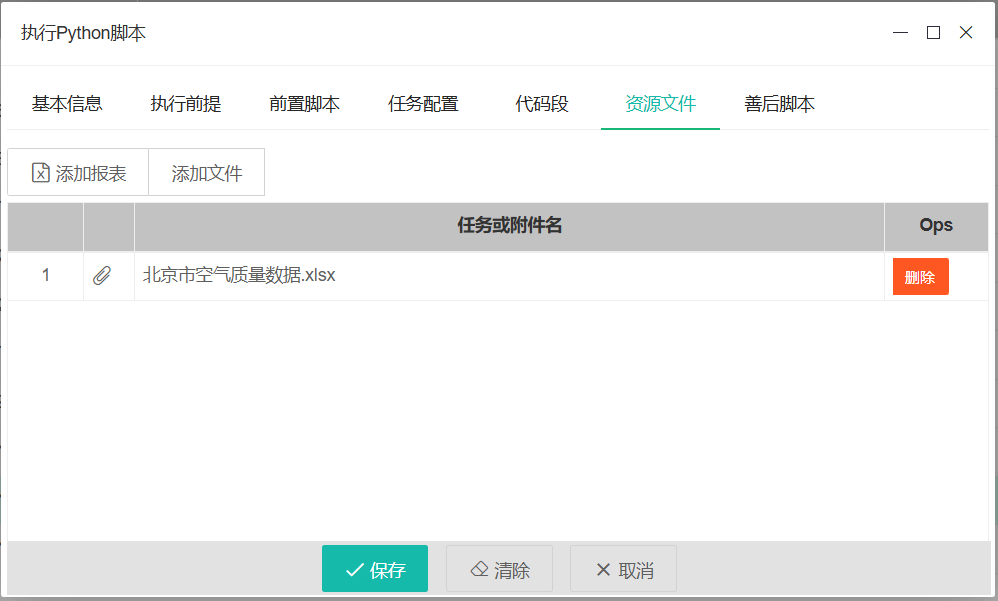
注:访问资源文件时,需要结合工作目录地址和文件名合并成最终的文件地址。如下代码:
import os
# 合并产生实际的文件地址
xlsPath=os.path.join(args.sys_working_folder,'北京市空气质量数据.xlsx')
# 读取数据文件内容
data=pd.read_excel(xlsPath)
结果输出
Python代码运行完成后,可以通过输出特定格式的结果来反馈给调用平台。仓鼠平台可以接收代码的反馈结果,并将执行结果更新到指定的自定义参数中,便于后续任务进行调用。
-
精简模式
该模式下,仓鼠系统读取代码执行时最后一个
print()输出的行信息作为执行结果,并复制给预指定的自定义运行状态变量(如果设置的话)。print('ok') -
高级模式
该模式下,仓鼠系统读取代码执行时输出的最后一个
print()输出的行信息,并解析成JSON对象,提取对应的属性errmsg值并赋值给预指定的自定义运行状态变量来标识当前任务执行的状态结果,并遍历results内的属性,按属性名称来自动匹配用户自定义变量名并赋值,完成返回结果的赋值。import json
# 创建符合要求的Python字典
data = {
"errmsg": "ok",
"results": {
"user_name": "johnson",
"file_name": "summary_report.png"
}
}
# 将字典序列化为JSON格式的字符串
json_string = json.dumps(data)
# 输出序列化后的JSON字符串
print(json_string)