数据结构同步
访问路径:数据功能 -> 系统任务 -> 数据结构同步
功能简述
该功能模块提供了提取外部数据源数据结构的功能,主要提供关系型数据库、结构性文件存储服务的结构同步能力。
关系型数据库
系统针对如下关系型数据库的表结构同步能力
- 数据源类型
- MS SQL Server
- Oracle
- MySQL
- PostgreSQL
- 同步对象
- 如果只是选择特定数据库,则系统将自动同步所有数据库中的表和视图对象
- 如果提供了特定的表名清单,则系统仅仅同步提供的表清单结构,匹配时,不区分大小写。(表清单可以通过分号、空格或回车符等进行区分多个表记录。如果Schema省略的话,系统将自动补齐特定关系型数据库默认的schema,如:dbo, public)
结构文件服务
系统提供如下的存储系统文件结构的提取能力,主要是xlsx, csv文件,如:
-
数据源类型
- SFTP
- Share Folder (共享目录)
- SharePoint 文档库
- MinIO
- AWS S3 文件桶
-
提取配置
针对结构性文件,在提取时需要做额外的配置信息,如结构提取开始行,和结构列的开始和截至列等。同时,针对特殊情况,系统提供如下选项来应对结构异常情况:
- 自动命名重名列: 如果选中,则在出现重名列时,系统自动在当前列名后添加序号以示区别。如:姓名,姓名_1,姓名_2。前面示例中后面2个列名均为“姓名”,系统自动添加后缀以示区别。
- 自动命名空白列:如果选中,当碰到未命名的空白列时,系统将获取当前空白列前第一个非空列名,并在此基础上添加序号,以创建对应的列名。如:地址,地址_1,地址_2,性别。前面示例中,地址_1,地址_2均为空白列名。
- 忽略空白或重名列:如果选中,则忽略出现的重名列,或空白列。该选项优先级高于其它选项。
SAP/BW数据源
系统支持SAP/BW中对应数据对象的结构提取功能,提取时需要提供具体的数据对象名称和格式,多个对象的查询格式符以分号或回车符连接。系统支持TABLE,ODP模式的结构查询,如果是DSO类型的BW数据源,需要通过SE11查询到对应的透明表名后,再以TABLE的格式进行查询。
例如:
| 数据对象 | 对象类型 | 查询格式符 |
|---|---|---|
EKET | TABLE | EKET,TABLE |
ZDS_WBS_LOG_NEW | ODP | ZDS_WBS_LOG_NEW,ODP |
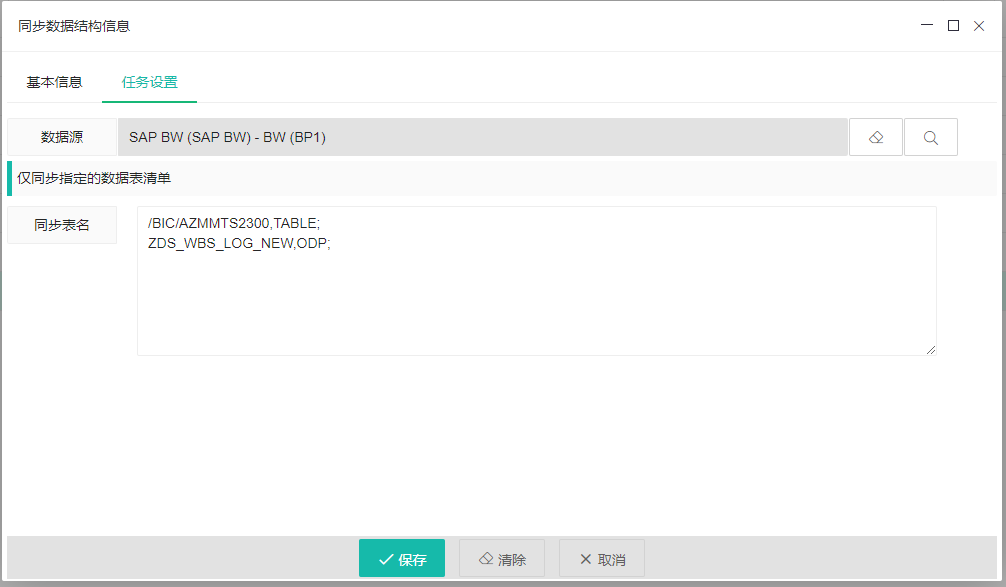
注:上图中为了演示,将BW和ECC中的数据对象放在一起展示,实际查询结构时,需要将对应的数据源(ECC、BW或APO)等数据源分拆后,再同步数据结构。
结构更新规则
数据同步后,系统将自动抽取数据源的结构信息到主数据库中,同时将进行如下操作:
-
数据表名同步
系统默认以schema和table_name进行匹配当前主数据库中的现有记录,匹配时不区分大小写场景,如果没有匹配上,则创建新表记录,否则更新当前表中记录。文件类型数据源中schema为空处理。在处理关系型数据库时,也会同步响应表的描述信息。
-
数据字段同步
- 系统默认先匹配字段名,匹配时不区分大小写场景。如果在当前表中未找到对应的字段,则新建,否则更新当前字段信息。
- 确认字段后,将继续匹配字段的其它信息,如字段类型、长度、精度、默认值、是否可空以及字段描述等信息,如有不同,将更新当前主数据库中对应的表字段信息。
- 在完成目标数据库所有表字段信息更新后,系统会更新本地主数据库中的同步标识,同时,将本地未被检测到的字段的可用标识调整成
is_enabled=false,标识当前字段没被检测到,可能已经在目标数据库中已被删除了。(被标注为不可用的字段将不可以被新任务引用到,但已经配置的任务仍然可以继续使用)