批量数据同步
访问路径:数据功能 -> 批量数据同步
功能简述
可以实现批量数据同步的模式,自动同步预置的数据表清单。针对特定批量的数据表(含关系型数据库、SAP、BW等数据源),将按给定的条件读取全字段列表。读取完成后,结果将以csv格式存储至预订的存储系统,如AWS S3、共享目录等。
任务脚本清单
可以通过特定条件来筛选需要查询的数据表清单,案例如下,其中<var:GROUP_WHERE/>为特定任务组变量,来筛选任务清单:
select
hm_data_object_id as data_object_id --Hamster数据库中定义的Database_Id
,data_object --表名或数据源名称
,data_source as source_name
,hm_database_id_prd as source_db_id
,data_module --数据源的业务模块名
,case extraction_mode when 'DELTA' then 'D' else 'F' end as extract_model --FULL全量获取,DELTA增量获取
,data_type as invoke_method --SAP数据抽取的模式:TABLE/ODP/DSO
,hm_data_filter as data_filter --数据过滤条件
,hm_data_object_location as data_location
FROM public.talend_workflow_source_list_loc
<var:GROUP_WHERE/>
上述脚本中各个字段的命名是固定的,相应含义如下:
| 字段名 | 参数描述 | 备注 |
|---|---|---|
| data_object_id | 数据对象Id | GUID,唯一标识当前数据对象 |
| data_object | 数据对象名 | 数据源中的数据对象名,如表名、视图名,或SAP中TABLE、ODP或DSO类型的数据对象名 |
| source_db_id | 数据源Id | GUID,唯一性标识特定的数据源,系统通过该ID来关联相应的访问账号信息 |
| source_name | 数据源名 | 数据源名称 |
| data_module | 数据模块 | 数据对象的分类模块名称,可用于数据存储的分类结构 |
| extract_model | 抽取模式 | 全量或增量抽取:DELTA:增量,FULL:全量 |
| invoke_method | 同步类型 | TABLE、ODP、DSO等类型 |
| data_filter | 查询过滤条件 | 针对不同类型数据源的数据对象的过滤条件 |
| data_location | 存储路径名称 |
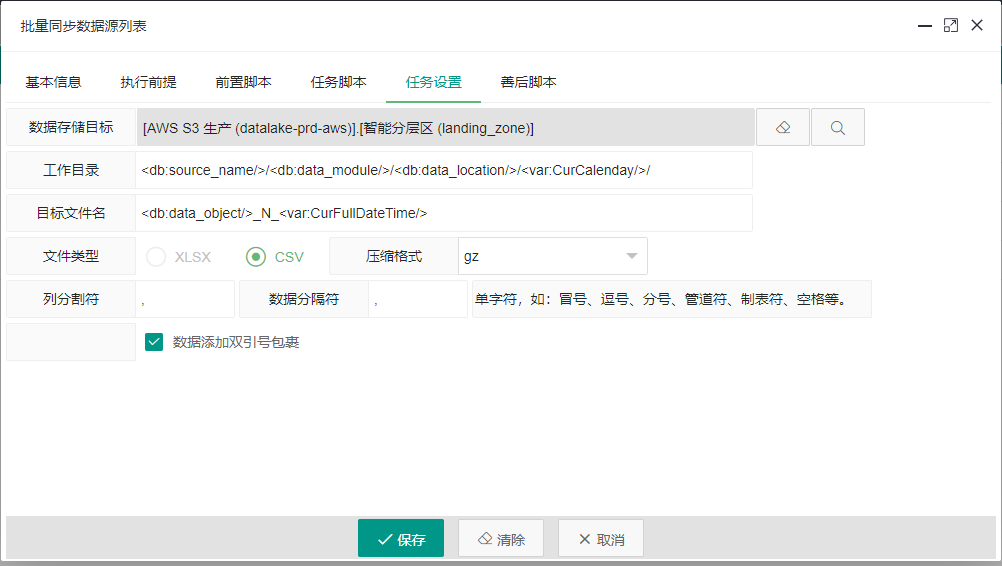
任务执行配置
该模块主要提供同步数据的目标存储地址信息,以及路径和文件名等信息的配置。参数清单如下:
- 数据存储目标:提供数据文件存储的目标数据源
- 工作目录:用于定义目标存储中的目录组成结构。可以使用系统变量和数据变量构成。
- 目标文件名:定义数据文件名的组成结构
- 文件类型:支持导出文件的文件类型
- 压缩格式:支持非压缩、zip、gz等压缩格式
- 列分隔符、数据分隔符:用于定义csv格式文件中数据项间的分割标识符。
- 数据添加双引号包裹:针对csv格式的数据项,添加双引号,确认不会因数据内部的特殊符号导致csv格式失效。
任务信息更新
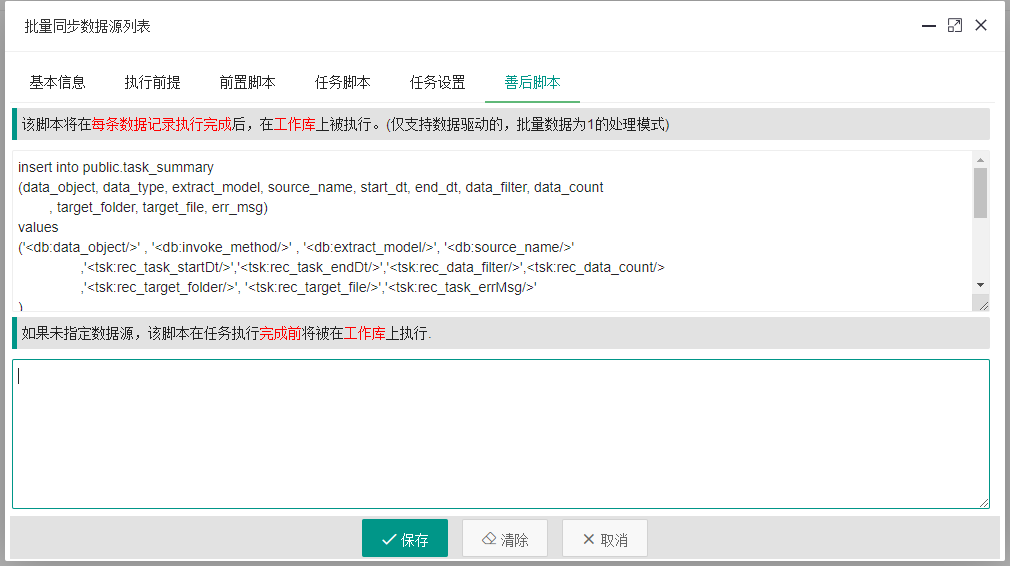
单表数据同步完成后,系统会自动更新任务级变量的内容,方便平台或用户查询或记录当前表数据同步的情况,该脚本将在善后脚本中的单条记录执行完成后被执行。具体任务变量清单为:
| 任务参数 | 参数描述 | 备注 |
|---|---|---|
<tsk:rec_task_startDt/> | 任务开始时间 | 日期 |
<tsk:rec_task_endDt/> | 任务截至时间 | 日期 |
<tsk:rec_data_filter/> | 数据过滤条件 | 文本 |
<tsk:rec_data_parsed_filter/> | 解析后的过滤条件 | 文本 |
<tsk:rec_data_count/> | 数据量 | 数字 |
<tsk:rec_task_errMsg/> | 错误信息 | 文本 |
<tsk:rec_target_folder/> | 目标存储路径 | 文本 |
<tsk:rec_target_file/> | 目标文件名 | 文本 |
<tsk:rec_target_uploaded/> | 数据上传标识 | 文本 |
上述任务级变量,可以通过善后脚本中的任务级脚本来实现数据的记录,脚本如下:
insert into public.task_summary
(data_object_id, data_object, data_type, extract_model, source_name
, start_dt, end_dt, data_filter, data_count
, target_folder, target_file, target_uploaded, err_msg)
values
('<db:data_object_id/>','<db:data_object/>' , '<db:invoke_method/>' , '<db:extract_model/>', '<db:source_name/>'
,'<tsk:rec_task_startDt/>','<tsk:rec_task_endDt/>','<tsk:rec_data_filter/>',<tsk:rec_data_count/>
,'<tsk:rec_target_folder/>', '<tsk:rec_target_file/>','<tsk:rec_target_uploaded/>','<tsk:rec_task_errMsg/>'
)
on conflict(data_object_id)
do update set
data_object=excluded.data_object,
start_dt=excluded.start_dt,
end_dt=excluded.end_dt,
data_filter=excluded.data_filter,
data_count=excluded.data_count,
target_folder=excluded.target_folder,
target_file=excluded.target_file,
target_uploaded=excluded.target_uploaded,
err_msg=excluded.err_msg;
任务完成状态
任务完成时,系统会再次更新系统环境变量来记录当前任务完成的状态。这些变量可以用于后续的提醒消息或邮件中。
| 变量名 | 备注 |
|---|---|
<var:SYS_REQUEST_TOTAL/> | 当前任务总数据源数 |
<var:SYS_REQUEST_COMPLETED/> | 已经完成同步的数据源数(含0记录的任务) |
<var:SYS_REQUEST_ZERO/> | 同步记录数为0的数据源数 |
<var:SYS_REQUEST_FAILED/> | 失败的数据源数 |
其它任务选项
当前任务中的前置脚本,善后脚本,分别在当前数据同步前、后执行,用于对同步数据进行预处理,和同步后的再清理计算等用途。可以根据场景需求采用。